virtual networking บน linux
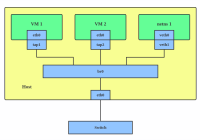
Linux has rich virtual networking capabilities that are… Read More »
Linux has rich virtual networking capabilities that are… Read More »

ติดตั้ง กำหนด Secret Key และผูกกับ App ตั้งค่า SSH Serv… Read More »

ก่อนจะไม่มี Repo CentOS 8.x ให้ใช้สะดวก ๆ แนะนำ Upgrade… Read More »

เพิ่มคำสั่งนี้ลงในไฟล์ /etc/ssh/ssh_config ของเครื่องปล… Read More »
ช่วงนี้เป็นช่วงที่ วงการคริปโตเงียบเหงาอย่างมาก ผมก็ไม่… Read More »
เริ่มกันเลยกับคำสั่งแรก คำสั่งเอาไว้ลบ default route 2.… Read More »

วันนี้ได้มีโอกาศทดสอบทำ zfs zpool mirror+cache+log ทดสอบถอด disk cache กับ log ออก พบว่า pool fail จะกู้ข้อมูลยังไง?
เปิดไฟล์ /etc/systemd/system/mysqld.service แล้วมองหา E… Read More »
ง่าย ๆ สั่งตามนี้เลย CentOS-Base.repo CentOS-SCLo-scl.r… Read More »
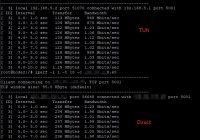
ผลทดสอบ iperf ** TUN คือทดสอบผ่าน vpn ** Direct คือทดสอ… Read More »
เรามีไฟล์ img ชื่อ backup.img เป็นไฟล์ที่โฟลดออกมาจาก S… Read More »
เปิดไฟล์ /etc/lightdm/lightdm.confทำการเพิ่มค่านี้เข้าไ… Read More »
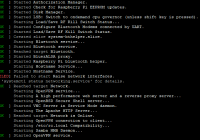
ปัญหานี้ผมก็ไม่ทราบสาเหตุแน่ชัดเท่าไรครับ แต่มันทำให้เค… Read More »

วิธีการ nat แบบ 1:1 ฝั่ง client ต้องใส่ gateway เป็นเคร… Read More »

สรุปจะอยู่ด้านล่างนี้ครับ สเปค server ที่ใช้ทดสอบVMsCPU… Read More »

สมมติเรามี proxy server อยู่คือ http://192.168.1.2:3128… Read More »
— Add these to speed up OpenCart ALTER TABLE `oc_… Read More »

timestamp คือ ชื่อ column เก็บข้อมูล to_date คือชื่อฟิล… Read More »

ใช้กับไฟล์ index.php ใช้กับไฟล์ 404.php ใน theme ที่ใช้
1.การแปลงไฟล์ virtual disk raw to qcow2 qemu-img conver… Read More »
พอดีได้ลองใช้ proxmox จริงๆ จังๆ สักที เหลือบไปเห็น OVS… Read More »

วิธีใช้คือ เอา code วางในไฟล์ แล้วสั่ง php -f ตามด้วยชื… Read More »
เนื่องจากต้องติดตั้ง VM จำนวนหลายสิบ VM ไหนจะต้อง set e… Read More »
เปิด console ขึ้นมาแล้วสั่งตามนี้ [cc lang=”cR… Read More »
[cc lang=”php”] /* https://stackoverflow.co… Read More »
